Improving Reliability, Part 1
Over the next month or so, I'm embarking on a journey to improve the reliability of @RemindMe_OfThis. You can see a summary of my plans in this GitHub issue. I'll also be writing about it. I plan to talk about the whats, hows and whys of the changes I'm making. So let's go!
Some Background
When I think of a service being reliable, here's what I think of:
- Behaviour: It functions as advertised.
- Availability: It has minimal downtime.
- Recovery: When the service does crash, it can be quickly restored to a good state with minimal data loss.
- Observability: It's easy for the makers to understand what's going on in it.
- Maintainability: It's easy for the makers to make changes.
The first three directly affect the end-user, so that's what most people think of when they hear "reliability". But, in my opinion, if the devs can't confidently gain insights from the service or make changes, then it will eventually become unreliable for the end-users, because that's software for you.
On side projects, we often skimp on these. (I'm guilty too.) For instance, we're willing to tolerate a project going down for several hours or occasional weird behaviour. We often skip proper backups, disaster recovery plans, or deploy/release/rollback workflows. Because they're low-stakes side projects, right? We aren't making serious money from them, people won't complain on Twitter if the service is down; why bother?
I think it's good engineering practice, though. It's kinda like "being faithful in the little things". Building reliable systems doesn't start when you go to work at Google. I believe that if you form the habit early on, it'll pay off dividends in your career. I don't want to over-engineer these small systems, but I do want to form a culture of making robust software.
So, in light of all this, I decided to practice what I preach and double down on this (especially as I'm writing a book on observability😅).
Today's changes: PR #20.
Fixing alerts
The first thing I had to do was figure out why I wasn't getting alerts from Sentry anymore. Recently, Sentry had stopped notifying me of new errors, even though it captures them. I'd dug through my spam, Sentry's settings and support pages, with no luck. Finally, I noticed the Alert Rules section and realised that it was empty. Odd. So I added a new alert.
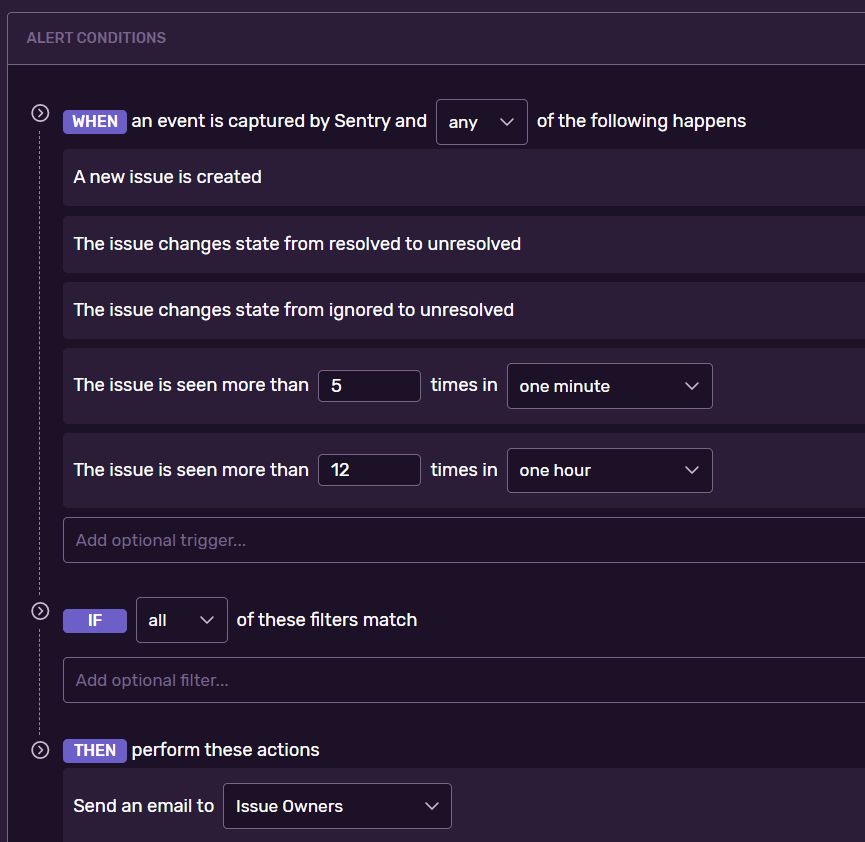
Now my error notifications are coming in again.👍
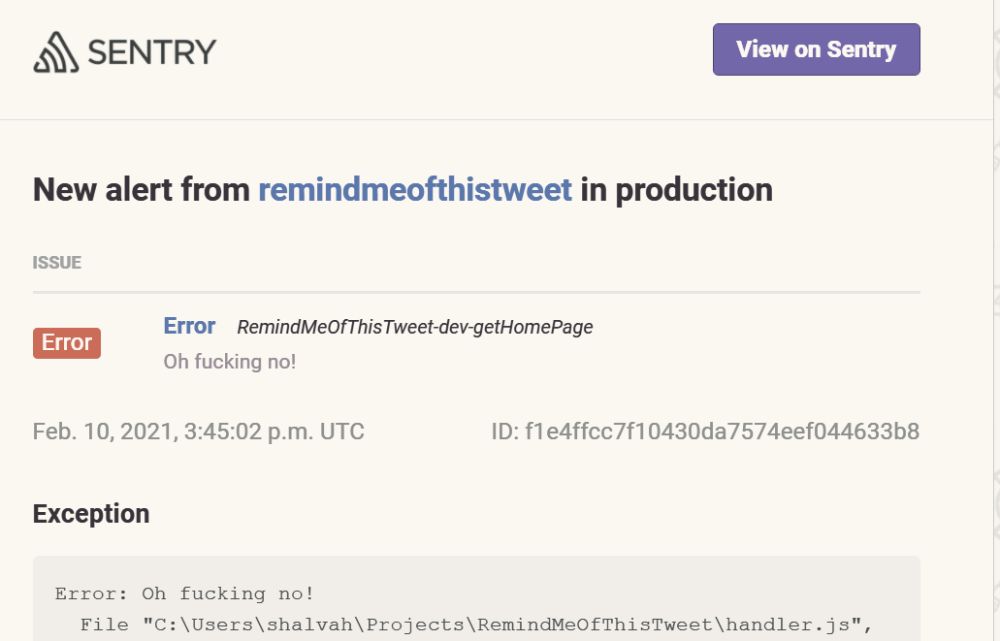
Why?
Without alerts, there are only two ways to know when something's wrong:
- Someone tells you.
- You check for yourself.
But you can't always be checking, and people won't always tell you. Recently, Twitter has been randomly locking the bot's account for no reason, and it's been fairly embarrassing for me to find out via people DMing me, "Hey, the bot's not responding". I want to be proactive, so I need these automated alerts.
Adding tracing and performance monitoring
This was the thing I really wanted to do. I'm a fan of Elastic APM's tracing features, and I know Sentry introduced theirs sometime last year, but I didn't know how to get it to work in AWS Lambda. Decided to take some time to do it today, and apparently, the key was in these lines:
const Sentry = require("@sentry/serverless");
const Tracing = require("@sentry/tracing");
Sentry.AWSLambda.init({
dsn: process.env.SENTRY_DSN,
tracesSampleRate: 0.4,
});
It seems that I needed to import @sentry/tracing and set a tracesSampleRate. The tracesSampleRate determines what percentage of traces are kept. For a service that has a lot of usage, you may not want to trace every request, for reasons like performance impact, storage and bandwidth. (To learn more about trace sampling, see this article). @RemindMe_OfThis is pretty popular, so I decided to start with a conservative value of 0.4. That means Sentry will only capture traces for 40% of all requests. I might increase it later, depending on how this performs.
Now I've got performance and tracing data coming in on Sentry:
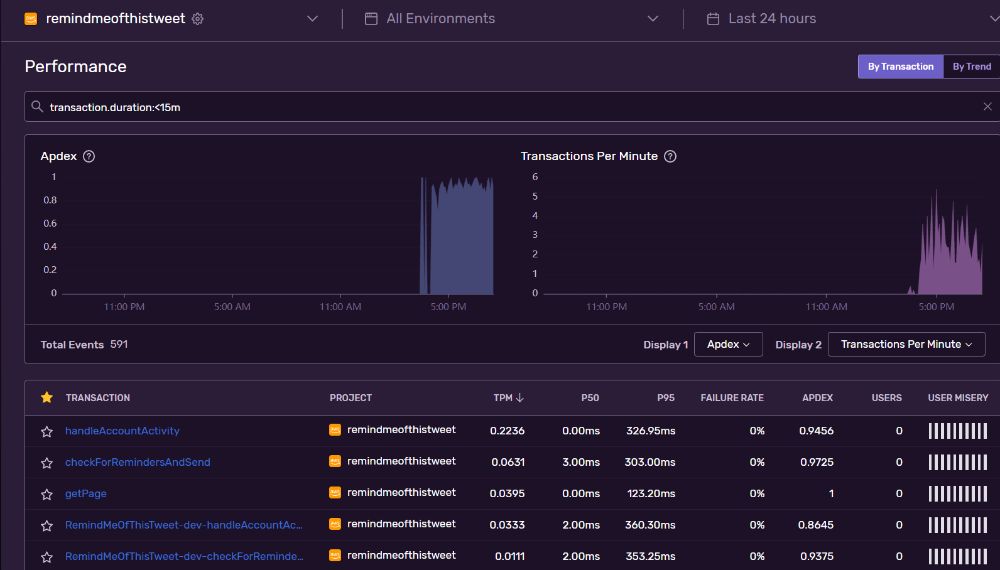
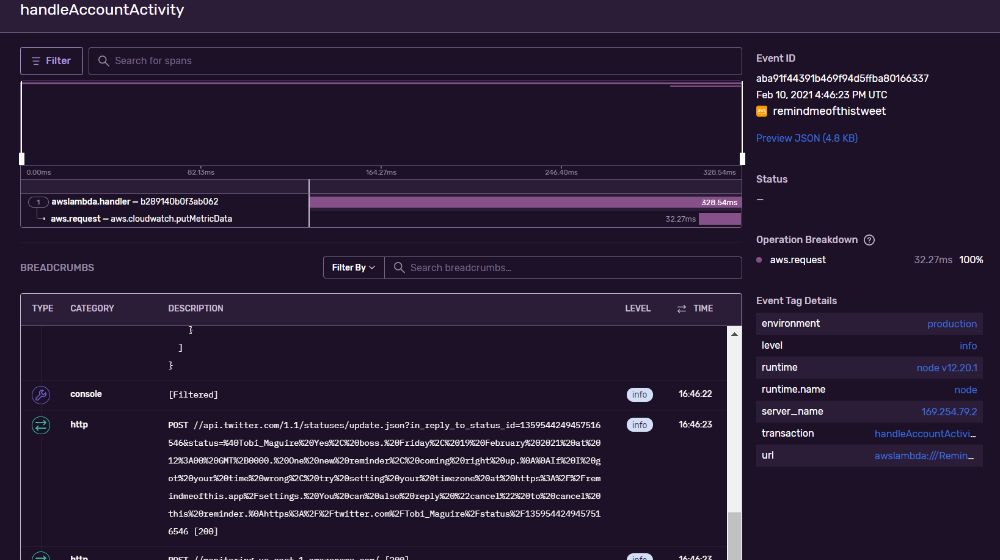
Why?
My goal for adding tracing is to get more insights into the service's behaviour. For instance, a while back, I debated whether or not to check if a user had changed their handle before replying to them. The deciding factor was "what impact will this extra API call have?" If I had tracing data, I could have looked at how long the Twitter API calls typically take and decided based on that. But as it was, I had to rely on local testing.
Proper tracing also gives room for experimentation. I could run an experiment in production where I make the extra API call occasionally, measure the impact and compare that with requests that don't have that API call.
Right now, the tracing data and graphs above might not make too much sense. Most of it is performance metrics, which I already had on AWS CloudWatch. But it's in a unified and friendlier interface now. And as time goes on, I'll add more instrumentation (see my post on instrumentation) and capture more relevant data.
Upgrading dependencies
The final thing I did was upgrading the Sentry SDK (v5 -> v6) and Firebase SDK (v8 -> v9).
One thing I've learnt the hard way: never upgrade major versions blindly. In the past, I've tried to do the "quick and dirty": upgrade a package to the latest major, run a few tests, and cross my fingers that nothing was broken. But that's no way to go if reliability is your goal. Your tests won't catch every possible scenario.
Instead, it's better to be intentional about upgrades. This means manually checking the changelogs to figure out what changed between versions before even deciding whether you should upgrade. It also involves choosing when to upgrade. Just because some shiny new features are out doesn;t mean you have to have them right now. Schedule an upgrade for when you have time to do it right and handle any fallout.
For instance, one of my key dependencies, chrono, is now on v2, whereas my project is on v1. I took a look at the changes and decided an upgrade wasn't worth it:
- For a sensitive feature like time parsing, a small change in the parser's behaviour can break a lot of things
- The
ParserandRefinerhave new interfaces. Considering that I've hooked into them quite a bit, upgrading will mean updating those changes too. And even though the new API might be objectively better, that upgrade isn't worth the cost (time and effort) right now.
Luckily, Sentry didn't contain any breaking changes, and the only ones in Firebase were in features I wasn't using.
(This is why writing changelogs is really important.)
Still, it's important to test after upgrades, because release notes don't always mention everything. Both locally and after release. So that's what I did:
For the Sentry SDK, I did a quick local test. I edited the code of a function to throw an error, and triggered the function locally with serverless invoke local: serverless invoke local --function getHomePage. Ran the function and checked my Sentry dashboard, and it worked—errors and trace information were being captured. After deploying, I hung around to monitor the dashboard and everything went fine.
Testing the Firebase SDK upgrade was harder. I use Firebase only for notifications, and the problem was that I didn't have a reliable way to trigger a notification without starting from the top (scheduling a reminder). It's something I'll fix as part of this project, but in the meantime, I had to work with what I had. Crossed my fingers, deployed, and tested it in production, and all was well.🙂
Why?
I wasn't really planning on making any upgrades yet. I decided to upgrade Sentry because their dashboard had been nagging me about it, and I didn't want to miss out on any new features. I upgraded Firebase because of a security issue reported by npm audit. I'm not sure if my app was directly affected by that issue, but that's the thing with security: what you don't know can harm you. It's better to be on the safe side.
What's next?
I'm not sure in what order yet, but the next things I'm going to focus on are better instrumentation, documentation and local emulation.
- Instrumentation will reduce guesswork when trying to figure out why an issue is happening,
- Emulation will help me reproduce and verify the behaviour of the service outside of the AWS Lambda environment.
- Documentation will make it easier for everyone — I can shift a lot of knowledge from my head, and others can more easily contribute or make their own version.
Final thought: I think reliability is the "next step" in engineering. You've written code that can convert files from one format to another. It works well on your machine, but what happens when 1,000 users are using it? 1 million? What if someone's using it on a slow connection, or in IE11 (if you care about that)? Reliability takes you from writing code that does X for a known number of users in a known scenario to writing code AND building supporting systems and processes that do X for an exponentially larger and unforeseen amount of users in near-infinite scenarios.
One of the things driving these changes is my realisation that I'm somewhat reticent in making certain changes to the app because I don't want to break anything. The aim is to eliminate that sense of fragility, to build systems that let you make all kinds of changes confidently.
As I go, I'll do my best to document the process. Stay tuned!
I write about my software engineering thoughts and experiments. Want to follow me? I don't have a newsletter; instead, I built Tentacle: tntcl.app/blog.shalvah.me.
