The UX of URLs
Let’s talk about something we see everywhere on the web: URLs.
URLs are addresses
A URL is an address to a property on the web. Just like a physical address, it points to one location.
People share addresses to help one another locate things. The same thing happens with URLs. You’ve probably copied a URL from your browser’s address bar and sent to a friend.
Imagine you were giving someone directions to retrieve a package from your office. In an ideal system, you’d probably give them an address like “Room 4, Floor 2, Building 4, Block C, 15 King’s Road, Queenstown”.
In a poor addressing system, you’d have to say something like “Go to the second street on your left, then keep walking till you get to a big tree. Enter the street opposite that tree…” — you get the idea. Still an addressing system, but a poor one.
Like addresses, URLs can be good or poor. Let’s look at some things that affect the UX of our URLs.
Hierarchy
An address is a pointer to one location. But when we see an address, we subconsciously grab metadata from it and make assumptions about the hierarchy. For instance, an address like Room 4, Floor 2, Building 4, Block C, 15 King’s Road, Queenstown tells you that there exists a Building 4 in Block C. So you might assume that there are other buildings in Block C. You might even go ahead to assume that these buildings would be numbered 1, 2, 3…. The address of a place is meant to give you a sense of hierarchy and layout.
A similar thing happens with URLs. When you see a URL like https://github.com/elastic/elasticsearch-js/issues/943#issuecomment-526816693, you might assume that there’s something at https://github.com/elastic/elasticsearch-js/issues/943, https://github.com/elastic/elasticsearch-js/issues, and so on, all the way back to https://github.com.
https://github.com
/elastic
/elasticsearch-js
/issues
/943
#issuecomment-526816693
It isn’t always so, though. For instance, as I write this post on Medium, this is what my address bar looks like:
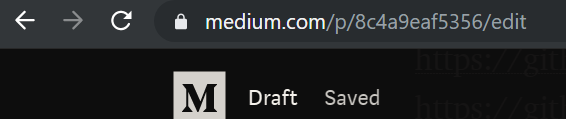
But visiting https://medium.com/p/ leads to a 404.
The same thing happens with a StackOverflow answer. This page exists (even though it’s a redirect): https://stackoverflow.com/a/4357014/7370522, but this page does not: https://stackoverflow.com/a/.
Similarly, you can visit https://github.com/elastic/elasticsearch-js/tree/master/api/index.js, but https://github.com/elastic/elasticsearch-js/tree gives you a 404.
It isn’t a rule that every path segment of a URL must lead to a specific resource. Sometimes there are good reasons to have a non-existent path. For instance, you could have a user’s profile be located at /users/<their-username>. But you might not have anything at /users, because you don’t want to display a list of all your users. A common convention is using single-letter segments like /p, /u, and so on. It indicates that this is done for technical reasons, but there really isn’t anything to look at there.
It’s good practice to try to maintain a hierarchy in the URL, even if it’s only theoretical (nonexistent pages). People look at the URL to get a sense of where they are on a website, similar to how we use physical addresses. It helps if there are obvious correlations, especially if the navigation on the page isn’t optimal.
Idempotent
With very few exceptions, URLs should be idempotent: the same path should always take a user to the same resource. For instance, the URL http://twitter.com/jack always takes you to the profile of a Twitter user with the username jack.
A few things to note here:
- The same resource, but not necessarily the same presentation
An example of this is when you’re showing different versions of your site to different users (A/B testing). So some users may see one layout and others a different layout, but it’s still the same page.
- The same resource, but not necessarily the same content
Visting https://twitter.com/notifications should take you to the Notifications page, but the content will vary, depending on the user that’s logged in.
This rule primarily applies to the path**.** Avoid using query parameters to determine what page a user is taken to. In my opinion, query parameters should only affect the presentation of the page at most, or the specific section or content shown to the user. The URL without those query parameters should still lead to the same page.
Redirects
Redirects are important because they change the URL in the address bar, and changes to the URL can potentially help or confuse users. It’s important to use redirects wisely.
Here are some scenarios where you should redirect:
- Someone tries to view a resource that needs authentication. It’s fine to redirect them to a login page and bring them back after they log in. This is a helpful redirect. You’re also not violating idempotency because the login page is a different page at a different URL.
- A resource has moved, maybe because you changed your website’s navigation structure. Cool URLs don’t change. Keep the old URL (perhaps for a limited time) and redirect to the new one.
And a scenario where you shouldn’t:
- A user enters a link to a nonexistent page (404 error). Do not change the URL to /404 (or /error or whatever). Changing the URL removes context for the user; they can’t inspect the URL in their address bar to determine where they made a mistake. Instead of the unhelpful redirect, it’s better to retain the URL and serve up a 404 page.
Storing transient state
This is particularly relevant in applications where the user can change the state of the page in ways that don’t get saved on the backend (hence “transient”) but may be a bit of a hassle or repetitive. Examples are entering search text, switching tabs, or changing the type of view. If we want our users to be able to easily share the page, along with their modifications, with others, we can store the current state in the URL. The canonical way of doing this is with query parameters and/or hash(#)-fragments.
Note that this only applies for “transient” state, state that holds no important or sensitive data and can be easily discarded or recreated, and it only works when the page is set up to update its content based on the URL (this can be done server-side or client-side).
Some good examples of this:
- GraphiQL, the GraphQL playground, stores the current query in the address bar. So you don’t need to copy the page URL and separately copy the query. If you have a page with a GraphQL query, and you share the URL of that page with someone, they will have the same query you had on your page.
 Note the `?query` query parameter in the URL, where the GraphQL query is stored. You can test this at http://graphql.org/swapi-graphql
Note the `?query` query parameter in the URL, where the GraphQL query is stored. You can test this at http://graphql.org/swapi-graphql
- The Elasticsearch UI, Kibana, does the same thing. It stores the current query, filters, selected date range and more in the URL. For instance, clicking this URL takes you to a page that has the query “this is my query” and a time range of “Last 3 minutes”: https://demo.elastic.co/app/kibana#/discover?_g=(refreshInterval:(pause:!t,value:0),time:(from:now-3m,to:now))&_a=(columns:!(_source),index:'filebeat-*',interval:auto,query:(language:kuery,query:'this%20is%20my%20query'),sort:!('@timestamp',desc))
- GitHub provides this functionality on most pages that have some form of search. If you visit https://github.com/shalvah?tab=repositories&q=laravel&type=&language=php, you’ll see a list of all my PHP repositories filtered by the term “laravel”. You didn’t need to copy the search term and filter from me separately; they’re part of the URL.
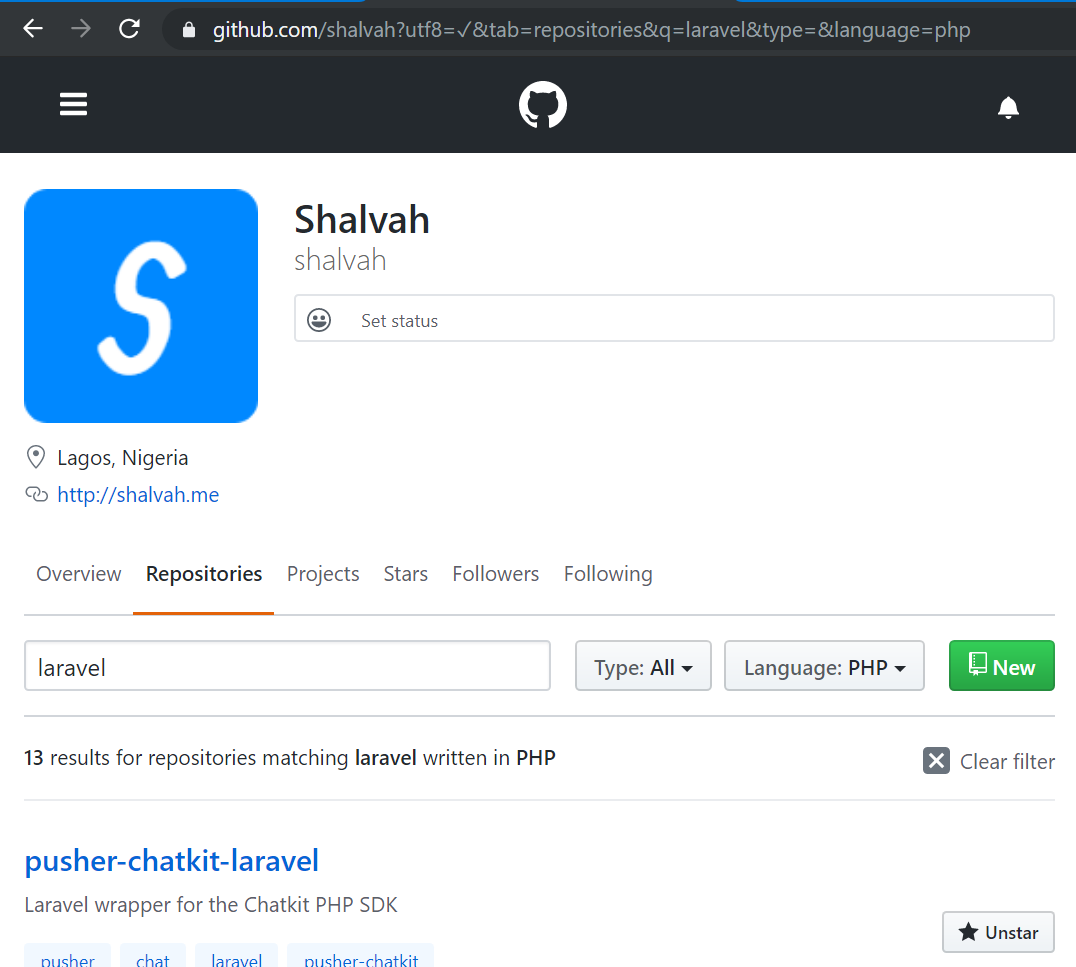
There are a few things to keep in mind here:
How much state should be stored in the URL?
Sometimes it’s not obvious how far to take the “store transient state” advice. For instance, in a chat app, should you store a pointer to the currently selected chat in the URL, or should you stop at /messages? Here’s what the URLs of some browser chat apps look like when you’re using them:
- Slack: https://app.slack.com/client/<team-id>/<DM/channel-id>

- Telegram Web: https://web.telegram.org/#/im?p=@user (the user you’re chatting with)

- WhatsApp Web: just https://web.whatsapp.com/
For chat apps, it’s important to think about how your app is used. What is the usage environment? How likely is your URL to be shared? How often will people look at our URL to get a sense of their surroundings?
Don’t put anything sensitive or disruptive in the URL
As a rule of thumb, anything that reveals information about a specific user (sensitive) or is specific to that user (potentially disruptive for others) shouldn’t go in the public URL.
An example of this is the contents of my cart. Imagine an e-commerce site that added the contents of my cart as query parameters in the URL. If I were looking at a single product and shared its link with my friend. When my friend opens that page, the contents of their cart will be overwritten with the contents of mine.
Such state should be stored on the user’s client (such as with local storage) or on the server, depending on the application.
Interoperability
Some sites have a separate subdomain they redirect you to when visiting from a mobile device — for instance, facebook.com vs m.facebook.com, twitter.com vs mobile.twitter.com. There could even be more variants like web.facebook.com. It’s important to ensure that links work across them.
A good implementation is Twitter’s. Both of these URLs — mobile.twitter.com/jack and twitter.com/jack — will take you to the same page, regardless of what platform you’re visiting from.
Here’s an example of a violation on a popular e-commerce site: jumia.com.ng/catalog/productspecifications/sku/HP246EL1G0J2PNAFAMZ
This is the URL you get when you click on a product’s description on jumia.com.ng from a mobile device. As of today, if you visit this URL on desktop, you get redirected to the homepage. This means when my friends share such a URL with me, I have to be on mobile to view the page they’re talking about, even though the same content exists on desktop as well.
Up-to-date
Ideally, a page’s URL should be updated when the page (not just the content) changes. This generally works out of the box in traditional, server-side apps, but is often overlooked in client-side apps, especially single-page apps that implement continuous scrolling or AJAX search. Here are some examples:
- On konga.com, when you enter a search term (example: “cars”)on the home page and hit Enter, the URL changes to https://www.konga.com/search?utm_source=search&search=cars, and you’re taken to the search results page for “cars”. But if you enter a new query on that page, while the search is executed, the URL is not updated.
- Google.com on mobile recently switched to using continuous scrolling for search results. Unfortunately, the URL remains the same regardless of how many pages you’ve scrolled through.
This oversight has two effects:
- When I share the URL with someone, they may not be looking at the same page I’m looking at, so you’ve broken the idempotence rule.
- You’ve also broken the browser’s Back button. If I click on a search result and then hit Back, the browser will likely take me back to the page that URL points to, rather than the last page I was looking at.
Friendly
Depending on your application, you should make your URLs as friendly as you can. For instance, Medium, WordPress and StackOverflow use a slug of the page’s title in the URL. Apart from improving SEO, it also makes it easier for a user that sees the URL to have an idea of what the page is about before even clicking the URL.
 On Medium: the URL contains a slug of the question title.
On Medium: the URL contains a slug of the question title.
 On StackOverflow: the URL contains a slug of question title.
On StackOverflow: the URL contains a slug of question title.
It’s not required, but if your application serves up structured media with defined titles, it’s a nice touch.
A few considerations
All of the principles we’ve gone over here are very useful, but they may not be relevant to your application. There are always exceptions. Here are a few things to consider:
- Are your URLs meant to be for the user or for the machine?
There are situations where you want your URLs to be obscure, usually in cases of security and access control. For instance, documents on Google Docs have very long and obscure URLs, even if they’re public.
Other times, you don’t really care about making them friendly, because the URLs are intended mostly for use by software. Here’s the URL of one of the images I used in this post (as uploaded by Medium): https://cdn-images-1.medium.com/max/1200/1*6iNLfxWlTyHA8ZsZkY3Whw.png. This URL isn’t designed for human readability because I’m not expected to use it directly much. My browser and the image server are the ones that are really concerned with this URL.
- Security considerations
On GitHub and GitLab, if you visit a private project, you will get a 404 page if you don’t have access to it, regardless of whether you are logged in or not. This seems to violate the idea of idempotency, but this is understandable, because in some scenarios, by revealing that there is something located at an address, even without making it open, you’re creating a vulnerability. For instance, if a thief came to your house, even if it were locked, depending on your resources, it might make more sense to pretend there’s nothing of value there, rather than admit there’s stuff to steal and spend energy keeping the thief out.
- What type of user are you building for?
Power users often edit URLs directly in the address bar because it’s faster than clicking buttons and waiting for multiple page loads. Most regular users are fine with using the navigation provided by the browser and your app. Both users, however, still rely on the URL to give them a sense of where they are. Depending on the application, it may be better to optimize URLs for one class of user.
- Some “big” sites violate many of these principles.
For instance, Facebook posts have cryptic, unreadable URLs. Youtube videos use a query parameter to determine the video you see. That doesn’t mean you should follow their example blindly, though. It’s important to understand how your application is being used or will be used and optimize that experience.
- Don’t forget navigation!
Even if your URLs are super friendly, it doesn’t excuse you from providing proper navigation function for your app. Headings, links, tabs, handling the Back button properly (for SPAs) — all of these make a good navigation system and go hand in hand with good URLs.
Remember that the URL is a source of truth. People trust URLs, and they share URLs. Let’s ensure that our application’s URLs are reliable and helpful to our users.
I write about my software engineering thoughts and experiments. Want to follow me? I don't have a newsletter; instead, I built Tentacle: tntcl.app/blog.shalvah.me.
