Experiments in concurrency 1: Single-threaded webservers in PHP and Node.js
Over the past few weeks, I've found myself encountering concurrency problems and discussions in a variety of places. I understand the basic principles of concurrency, but I haven't had as much hands-on experience as I'd like, so I decided to learn by running some experiments and writing about them.
Experiment 1: PHP's built-in server has zero concurrency
PHP comes with a built-in server. php -S localhost:8000 -t myapp/ will start a simple server for your app. Some frameworks provide a wrapper around this (php artisan serve). But all of them refer to it as a development server, meaning you should not use it in production. One reason for this is that it's single-threaded by default. It runs as a single thread, so each request is served by the same thread. And since PHP is synchronous, that means each request has to wait for the previous one to finish.
I've known this for a long time, but I wanted to prove it to myself, just for the fun of it. So I did a quick test:
I created a global middleware that runs on every request and logs request start and finish:
class Check
{
public function handle(Request $request, Closure $next)
{
ray("Starting: ". $request->fullUrl());
sleep(10);
$response = $next($request);
ray("Finished: ". $request->fullUrl())->green();
return $response;
}
}
Then I opened several browser tabs and reloaded them simultaneously. Sure enough, each request logged its "Starting" and "Finished" 10 seconds apart, one after the other. There were never any overlapping requests.
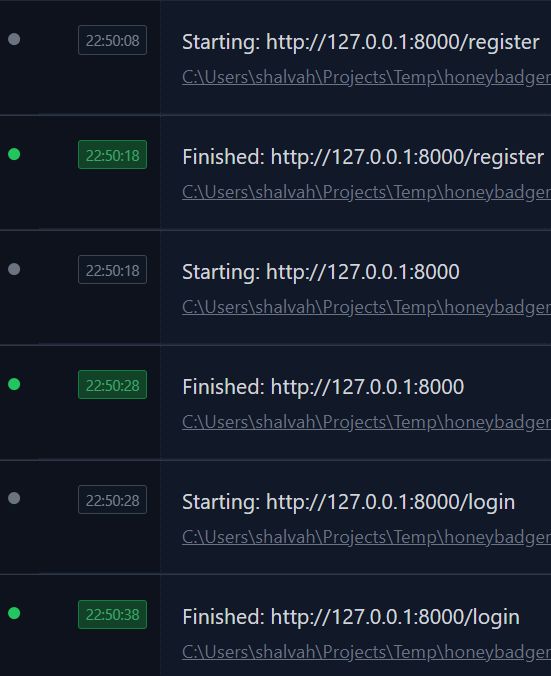
Welp. Imagine what a problem this would be in production. Every user would have to take turns accessing the website, because it can't handle multiple requests at the same time.
Why is this?
The reason for this is PHP's synchronous execution model. PHP is meant to die. PHP's execution model is straightforward: start up, execute your commands, then exit. There are no event loops, worker threads, or coroutines to worry about. Everything executes one after the other. This is one reason why it's a simple language to wrap your head around.
But when you combine this lack of asynchronicity with a single-threaded server, you get request handling that doesn't "scale".

Aside: PHP 7.4 introduced the experimental PHP_CLI_SERVER_WORKERS variable that lets the server handle concurrent requests, but that's beyond our scope right now.
How about Node.js?
Node.js also runs as a single-threaded server. But Node.js comes with inbuilt asynchronicity and event-driven I/O. So does it still have this problem? Well...yes and no.
First off, the request handler in Node.js is actually called synchronously (one after the other). This is important, because a lot of people assume events fired in Node.js are handled asynchronously. They aren't. The Node.js server uses a similar loop as the PHP server above: pick a request, execute its handler, move to the next request.

I ran another experiment to verify this:
const requestHandler = function (req, res) {
console.time(req.url);
console.log(`Starting: ${req.url}`);
let i = 0;
while (i < 100_000) {
const data = fs.readFileSync(__filename);
i++;
}
res.writeHead(200);
res.end('Hello, World!');
console.log(`Finished: ${req.url}`);
console.timeEnd(req.url);
}
const server = http.createServer(requestHandler);
server.listen(3040);
This code is totally synchronous, like with PHP: I'm reading from a file 100,000 times, just to create some fake work for the server to do that takes time.
Next, I fired off three requests around the same time, and...
Starting: /
Finished: /
/: 4.414s
Starting: /ping
Finished: /ping
/ping: 4.269s
Starting: /dfd
Finished: /dfd
/dfd: 4.281s
Well, whaddya know? Even though I started the requests at the same time (Shift + click to select multiple browser tabs, right-click > Reload), the requests were handled one after the other. Each request had to wait for the first to finish before it could be attended to.
Let's change things a bit:
const readFileManyTimes = (i, callback) => {
fs.readFile(__filename, (err, data) => {
if (i < 100_000) {
readFileManyTimes(++i, callback);
} else {
callback();
}
});
}
const requestHandler = function (req, res) {
console.time(req.url);
console.log(`Starting: ${req.url}`);
readFileManyTimes(0, () => {
res.writeHead(200);
res.end('Hello, World!');
console.log(`Finished: ${req.url}`);
console.timeEnd(req.url);
});
}
We're still reading from the file 100,000 times before sending a response, but now we're doing it asynchronously.
This time, the results are different. The requests are handled concurrently:
Starting: /
Starting: /ping
Starting: /dfd
Finished: /
/: 11.415s
Finished: /ping
/ping: 11.415s
Finished: /dfd
/dfd: 11.420s
If you're familiar with concurrency, these results shouldn't be too surprising. Concurrency doesn't mean doing multiple tasks in parallel. Rather, it involves a number of strategies that let you smartly switch between those tasks so it looks like you're handling them at the same time. The major benefit of concurrency is to not keep any one person waiting for too long.
To the uninformed, it might look like Node.js is executing all three requests at the same time, but it really isn't. The key difference is the asynchronous file read, that allows for the Node.js process to hand off that to the operating system and switch to another task.
So, no. Node.js won't have the same concurrency limitation as PHP for most web apps, since most of its I/O-bound operations are asynchronous by default, but if you write synchronous code, you'll get synchronous results. In the first example, our use of synchronous file reads turned our concurrency into zero.
Knowing this can help you avoid some frustrating bugs and debugging problems. For example, your users might be complaining that your site is slow, but when you add some code to measure your response times, it tells you requests are being handled in a second or less. Since each request is only handled after the previous one, if your code is synchronous, there's no way to record the exact time the request was actually sent. A solution to that would be to monitor your response times from the outside, not the inside of your application.
Concurrency vs latency
This is a bit of a diversion from my original intent, but an interesting thing to look at here is the tradeoff between concurrency and latency. In the synchronous example, each request was handled in about 4 seconds.
In the concurrent version, each request took around 11.4s. That's a lot more. But there's an important factor: wait time. In the synchronous version, each request had to wait for previous ones before it could be handled. So while it was handled in only a few seconds from our end, the user might have been waiting for a minute or more already. To get the true response time from the user's end, we need to add the time it spent waiting for the previous requests:
| Request | Handled in | Wait time | Actual response time |
|---|---|---|---|
| / | 4.4s | 0 | 4.4s |
| /ping | 4.3s | 4.4s | 8.7s |
| /dfd | 4.3s | 8.7s | 13s |
So one unlucky person had to wait 13 seconds. The difference betwen concurrent and synchronous versions here isn't much because we only tested with 3 concurrent requests. Imagine if we had 50 requests at the same time, with each request taking 4s. That means we would have a response time as large as (4 * 50) = 200s. I tested this with autocannon:
❯ autocannon --connections 50 --amount 50 --timeout 10000 http://localhost:3040
Running 50 requests test @ http://localhost:3040
50 connections
50 requests in 208.69s, 7.7 kB read
Sure enough, the last request was handled in 4 seconds, but it took 208 seconds from when the request was sent to when it was finally handled.
Here's what happens with the concurrent version:
❯ autocannon --connections 50 --amount 50 --timeout 10000 http://localhost:3040
Running 50 requests test @ http://localhost:3040
50 connections
50 requests in 122.73s, 7.7 kB read
In this case, we've saved on our overall wait time—users won't have to wait for more than 122s—but we've lost on our average response time —everyone now has to wait for 122s. So, even concurrency isn't a silver bullet—it helped us handle multiple requests at the same time, but it took longer because we're doing a lot at once.
Still, 122 seconds is an awful lot of time to expect the user to wait for a response. But you shouldn't have to worry about that. In the real world, your APIs should be returning responses within a second, so a concurrent setup would be able to handle 50 requests in a few seconds.
Overcoming the limitations
Handling multiple requests is a requirement for any web app, but moreso if you're running a highly interactive application such as a websockets server. Forcing each connection to wait for previous ones will likely lead to the socket timing out before you get to it. In a non-web context (such as games), user interactions will hang if every single interaction and the actions it causes has to be processed before anything else can be done.
So how do we get around this single-threaded limitation and achieve (better) concurrency?
The direct answer: add more threads! We can increase the number of threads by adding more servers. If I start multiple PHP or Node.js servers with a load balancer that distributes requests between them, then I would be able to handle more requests concurrently.
Spinning up new processes can be an expensive operation. Dedicated servers like Apache and Nginx do this more efficiently—they handle the creation and management of processes or threads for each request. Here's a good read on how Nginx does it.
If you'd still like to achieve concurrency within a PHP server, there are a few projects that try to provide this, the most notable of them being ReactPHP and Amp. The recently released Laravel Octane also provides this, with a much cleaner API over another project, Swoole.
Here's what a concurrent webserver looks like with Amp:
use Amp\Http\Server\RequestHandler\CallableRequestHandler;
use Amp\Http\Server\HttpServer;
use Amp\Http\Server\Request;
use Amp\Http\Server\Response;
use Amp\Http\Status;
use Amp\Socket\Server;
use Psr\Log\NullLogger;
use Amp\Loop;
Loop::run(function () {
$sockets = [
Server::listen("0.0.0.0:8080"),
];
$server = new HttpServer($sockets, new CallableRequestHandler(function (Request $request) {
ray("Starting: ". $request->getUri());
$file = yield \Amp\File\get(__FILE__);
ray("Finished: ". $request->getUri())->green();
return new Response(Status::OK, [
"content-type" => "text/plain; charset=utf-8"
], "Hello, World!");
}), new NullLogger);
echo "Server running at http://127.0.0.1:8080\n";
yield $server->start();
});
Yep, overlapping requests.✅

Concurrency comes with its own challenges. It complicates things. Your code has to be aware that it will be run concurrently, otherwise you will fall victim to a lot of bugs. And there's a whole class of concurrency problems in computer science, that people have studied and tackled for decades. But it's extremely important in providing a good user experience, and I hope to get better at reasoning about it as I go.
I had fun running these experiments to verify some of my assumptions about the platforms I use, and I hope you enjoyed reading! Experimenting is such a great way to learn. I recommend running the experiments yourself, and even designing your own.
I write about my software engineering thoughts and experiments. Want to follow me? I don't have a newsletter; instead, I built Tentacle: tntcl.app/blog.shalvah.me.
