In programming, serialization is the process of transforming data so it can be transferred, stored, or compared. You might have a variable in your program that holds some data, such as a list of users, but you need to pass that data to something or someone else, such as another program or a consumer of your API. However, this variable only exists in your program's memory, in some format specific by your language and operating system. You can't simply pass the variable to someone else; you have to serialize it.
Another use case for serialization is comparing complex objects. In many languages, objects can hold data (properties) as well as actions (methods), but you will only want to compare specific data. It's often easier to convert both objects to a common simpler primitive (like a string) and compare that, rather than iterate over each one's properties.
Human-readable vs binary
When serializing a value, we convert it to a different sequence of bytes. This sequence is often a human-readable string (all the bytes can be read and interpreted by humans as text), but not necessarily. The serialized format can be binary. Binary data (example: an image) is still bytes, but makes use of non-text characters, so it looks like gibberish in a text editor. Binary formats won't make sense unless deserialized by an appropriate program. An example of a human-readable serialization format is JSON. Examples of binary formats are Apache Avro, Protobuf.
Here's how a {hello: "world"} object looks like in JSON versus Protobuf:
- JSON (17 bytes)
{"hello":"world"}
- Protobuf (7 bytes):
// interpreting the bytes as Unicode characters...
\n\u0005world
// reading them as a sequence of bytes in raw hexadecimal form...
0A 05 77 6F 72 6C 64
// or as binary...
00001010 00000101 01110111 01101111 01110010 01101100 01100100
Anyone can create a serialization format. For instance, we could choose to represent our {hello: "world"} object like this:
type: object
properties: 1
name: hello
value: world
It's silly, but as long as the consumer understands how to reconstruct {hello: "world"} from this, then we're good. However, there are a lot of existing serialization formats, so we shouldn't need to create custom ones.
Tradeoffs in serialization
Why are there different serialization formats? Because different applications have different needs and constraints, and we're constantly looking for the best match for our needs. Some of the major tradeoffs involved when picking a format are human-readability, ease of debugging, speed, and payload size.
Binary formats are often faster to parse and result in smaller payloads. For instance, we could build a gRPC API that uses Protobufs as its serialization format. You can see from our example above that the Protobuf version of {hello: "world"} is only 7 bytes, less than half the size of the JSON version. This means our API would be sending out much less data, which can be really helpful for APIs with gigantic payloads. But we lose the human-readability and debuggability: you can't just inspect the response in your browser.
Most APIs today go with JSON. It's not the most optimized in speed or size, but it's fast enough and can be easily debugged, making it worth it, unless your API is transferring humongous amounts of data.
A note on schemas
By the way, why is the payload size for Protobuf so small? The key is the schema. To generate this hello world payload, we first need a schema declaration file:
syntax = "proto2";
message HelloWorld {
required string hello = 1;
}
We then load this file, and it creates the needed classes and types in our code:
const protobuf = require("protobufjs");
// Load the schema
const root = await protobuf.load('helloworld.proto');
const HelloWorld = root.lookupType("HelloWorld");
// Create the payload
const message = HelloWorld.create({hello: "world"});
const buffer = HelloWorld.encode(message).finish();
You can see that the output message which we saw earlier contains the "world" string verbatim (726C64 in hexadecimal), but does not contain the "hello". That's because the client on the other end should also have a copy of the schema. That way, when it receives the message, it knows the structure and which fields have which values. This is how so much space is saved. Clever.
Interesting tidbit: the HTTP protocol
Here's a fun point of view: HTTP isn't really a protocol in the traditional sense. It's a format for certain messages sent over TCP (Transmission Control Protocol). In fact, we can think of HTTP as a serialization format: you create a request object that describes what you want, then you serialize it and send it over TCP to a server which deserializes it and responds. For instance, when you request the Google home page, your serialized HTTP/1.1 message looks like this (the blank lines at the end are intentional):
GET / HTTP/1.1
Host: www.google.com
Content-Length: 0
Connection: close
You can test this! If you're on Linux, Mac or WSL, put the above in a file, raw.http (don't forget the two blank lines at the end) and pipe to netcat like this:
cat raw.http | nc www.google.com
You'll get the Google homepage as raw HTML.
As you can see, HTTP/1.1 is a human-readable format. You can write a simple HTTP/1.1 message by hand and send. Unfortunately, HTTP/2 isn't. I don't have a copy of a HTTP/2 message to show you, but HTTP/2 is a binary format. Thankfully, most people only interact the parsed HTTP requests, so this shouldn't matter much.
Exploring some more formats
XML and JSON
You're already familiar with these two, but I'd like to point out some specific features. First, here's what an XML {hello: "world"} object might look like:
<object>
<hello>world</hello>
</object>
This is only one possible representation, though. XML is an eXtensible Markup Language, so you create and use your own tags. Here I chose to use a generic <object>, but I could use a <HelloWorld> tag instead, as long as the client expects the same schema. This allows for XML to easily support types, like Protobuf. The client loads the XML and gets instances of HelloWorld or whatever class you're using.
Unfortunately, XML has a number of annoying issues. It's human-readable, yet too noisy to be read comfortably. It's also larger in size—the example above is 37 bytes, excluding whitespace, more than twice the JSON version.
Another problem with XML is that it isn't always obvious whether to use attributes or elements. For example, here's an alternate version of our example:
<object>
<hello value="world" />
</object>
or even:
<object hello="world" />
This can lead to some confusion, as different tools might expect different formats for the same data.
These limitations bring us to JSON. JSON is based on (but independent of) JavaScript, so custom elements are replaced by generic objects. The noise from multiple opening and closing tags is removed, making it easier to read and smaller in size.
JSON has only basic types, so anyone wanting to communicate type information has to do so themselves. You can use a spec like JSON Schema to define the schema for your clients. JSON:API builds on this by letting you include the schema in the payload, at the cost of increased payload sizes.
Since JSON is fairly human-readable and human-writable (when it's small in size), it has become quite popular and is now commonly used for other purposes, such as writing config files and databases. But it wasn't designed for that, so many extensions or supersets of JSON have been developed to work around its limitations: YAML replaces the braces with whitespace for easier readability, JSONC is JSON with Comments, JSON5 makes it more JavaScripty, and HJSON and RJSON remove many restrictions. And then there's MongoDB's BSON ("binary JSON"), which is a binary format (not human-readable) based on JSON.
PHP and Ruby
Some programming languages also define their own serialization formats. You'd typically use these when working within the same application, when you need to save some state and resume later. For instance, in Laravel, you define background jobs as a class. When you dispatch a new job, Laravel serializes it into a string and saves in the database where it can be picked up later by a queue worker and deserialized into the job class.
PHP has the global functions serialize() and unserialize. An example:
class HelloWorld
{
public function __construct(
public string $hello
) {}
}
echo serialize(new HelloWorld("world"));
This gives:
O:10:"HelloWorld":1:{s:5:"hello";s:5:"world";}
It's not designed to be human-readable, but it's not binary, either. It's not JSON; it's just a compact way of representing objects. Basically this means:
O: // -> type: object
10: // -> length of the object's name
"HelloWorld": // -> the object's name
1: // -> number of properties
{
s:5:"hello"; // -> type (string), length (5), and value of property name
s:5:"world"; // -> type (string), length (5), and value of property value
}
You can read more about the format on WIkipedia and the PHPInternals book.
The benefits of PHP having its own serialization system (as opposed to using JSON or something similar):
- It supports full class information, from the class name to the field values. Almost any class can be serialized, and you can override the serialization/deserialization process for your custom classes.
- It's more compact. This is useful because objects can be very large and contain other objects.
- It supports references. If you serialize an object or an array where a certain object is referenced more than once, it is only serialized in full once. For instance, in the example below,
$h1is referenced twice, first as itself, then as$h2.
$h1 = new HelloWorld("world");
$h2 = $h1;
echo serialize([$h1, $h2]);
// Result:
// a:2:{i:0;O:10:"HelloWorld":1:{s:5:"hello";s:5:"world";}i:1;r:2;}
In the serialized string, the second item in the array (i:1) has a value of r:2, which indicates that it is a reference to the second serialized entity (the first is the array, second is the first object). Thus, when we deserialize this string, we'll get two new objects which are exactly the same, just like the original.
$serialized = serialize([$h1, $h2]);
[$newH1, $newH2] = unserialize($serialized);
var_dump($newH1 === $newH2); // bool(true)
Ruby's format is similar but even less readable, since it includes non-text characters. Serialization in Ruby is done via Marshal.dump and Marshal.load.
class HelloWorld
def initialize(hello); @hello = hello; end
end
h1 = HelloWorld.new("world")
p Marshal.dump(h1)
# Result:
# "\x04\bo:\x0FHelloWorld\x06:\v@helloI\"\nworld\x06:\x06ET"
Note that it might look longer than the PHP version, but it's actually smaller (37 bytes vs 46 bytes)—characters like \x04 are a single byte, not 4.
Here's a breakdown of this string:
\x04\b # -> version of Marshal format (= "\x04\x08" = 4.8)
o # -> type: object
:\x0FHelloWorld\x06 # -> class name and number of instance vars
:\v@hello # -> instance variable name
I\"\nworld\x06 # -> value: type string (`\"`), and number of instance vars
:\x06ET # -> the encoding of the string, as an instance var
Full explanation of the format here.
MessagePack
Finally, since we're moving into the world of less human-readable, here's another interesting format: MessagePack. It uses similar principles to PHP's and Ruby's: sequence of bytes, with shortcuts to represent types. Our {hello: "world"} in MessagePack is now (as a sequence of bytes):
81 A5 68 65 6C 6C 6F A5 77 6F 72 6C 64
As the MessagePack homepage explains, this breaks down to:
81 -> 1-element map
A5 -> string with 5 characters
68 65 6C 6C 6F -> the string ("68656C6C6F" = "hello")
A5 -> another string with 5 characters
77 6F 72 6C 64 -> the string ("776F726C64" = "world")
You'll notice that a lot of these optimized formats include the length of the next item before writing the item. This is a useful optimization—when you know the size of the incoming data, you can allocate the exact amount of memory ahead of time, rather than create an empty array/object and resizing it as you go.
Here's a playground where you can test out Protobuf vs MessagePack conversions.
Fun experiment: Creating a custom serialization format
As an exercise, let's try to create our own format, with a twist: it produces an image.
Well, not really. Technically, it will produce a sequence of bytes, just as all others do. But, in this case, these bytes will also form a valid image. All that's needed is to define a way to encode your data as pixels. So let's define our spec.
To keep things simple, we'll only support objects and (ASCII-only) strings. An object will be represented by a red pixel, followed by a pixel denoting the number of keys in the object, then each key and value, serialized. Strings will be a green pixel, followed by a pixel for the length of the string, then the string value. So, {hello: "world"} should be:
pixel(obj) pixel(obj.keys().length) pixel(str) pixel("hello".length) pixels("hello") pixel(str) pixel("world".length) pixels("world")
We know that pixel(obj) and pixel(str) are red and green respectively, but we haven't decided yet what the pixels for the numbers and words will be. We'll come to that soon.
Now, we want to create a sequence of bytes that correspond to an image. But different image formats have different specifications. For instance, PNG uses a different sequence of bytes to describe an image than JPEG does. And they're all fairly complex, since they account for compression, image metadata, and things like that. So we'll stick to something simple: the HTML canvas element, and its helper object, ImageData. With ImageData, an image is simply a series of bytes, where every four bytes represents one pixel. The four bytes describe the colour of that pixel— Red, Green, Blue and Alpha (transparency) values, in the range 0-255.
This means that our object and string pixels, red and green will be:
R G B A
Red: FF 00 00 00
Green: 00 FF 00 00
Each two-character group represents one byte in hexadecimal (base 16), so FF = 255.
That one was pretty easy. For the numbers, we can simply repeat the value 4 times. For example, "hello".length is 5, so we can encode this as 05 05 05 05. This is valid, but it will produce a pretty dull image. This pixel will be grey, since R, G and B all have the same value. So we can switch things up a bit by setting only one byte to the number, and the rest to 0, except for the alpha, which we always set to 255 (FF) so the pixel isn't transparent at all. So, assuming we pick the second byte as the "truth" byte, we have:
00 05 00 FF
This will give us a nice green colour, rather than grey. To add some "flavour", we can randomize the position of the truth byte. For instance, serializing 5 again might give 00 00 05 FF instead. While this means our format isn't idempotent, it's still deterministic, because we know we just need to find the first non-zero byte when deserializing.
Next up, representing string characters. Doing this is also pretty simple: convert each character to its character code. We mentioned earlier that only ASCII strings are supported; this makes it easier, because ASCII character codes range from 0-127 (7F in hex), so we know we can fit them in one byte. This means emojis and special characters like ß won't be serialized correctly, but that's an exercise for another day!
Okay, so we take the character code and apply the same treatment as above: put it in a random truth byte, set the other two bytes to 0, and set alpha to FF. So, "h" could be:
68 00 00 FF
(because the ASCII code for "h" is 104, which is 68 in hex).
Nice! That's all we need. Let's write our serialisation algorithm:
const RED = [0xFF, 0, 0, 0xFF]; // R, G, B, A
const GREEN = [0, 0xFF, 0, 0xFF];
function serialize(val, outputBytes = []) {
if (typeof val === "string") {
serializeString(val, outputBytes);
} else {
serializeObject(val, outputBytes);
}
return outputBytes;
}
function serializeObject(obj, outputBytes = []) {
outputBytes.push(...RED);
const keys = Object.keys(obj);
outputBytes.push(...wrapInRGBA(keys.length));
keys.forEach((key) => {
serialize(key, outputBytes);
serialize(obj[key], outputBytes);
});
return outputBytes;
}
function serializeString(str, outputBytes = []) {
outputBytes.push(...GREEN);
outputBytes.push(...wrapInRGBA(str.length));
for (let i = 0; i < str.length; i++) {
outputBytes.push(...wrapInRGBA(str.charCodeAt(i)));
}
return outputBytes;
}
function wrapInRGBA(value) {
const rgba = [0, 0, 0, 255];
const truthByte = Math.floor(Math.random() * 3);
rgba[truthByte] = value;
return rgba;
}
This is our serialization logic. It returns an array of numbers, with every four numbers representing the RGBA values of a pixel. Obviously, it has limitations (for instance, it can't serialize objects with more than 255 keys), but it'll do for us. Here's what we get for our hello world example:
const obj = {hello: "world"}
const serialized = serialize(obj);
console.log(serialized);
// [
// 255, 0, 0, 255, 0, 1, 0, 255, 0, 255, 0, 255,
// 0, 5, 0, 255, 0, 0, 104, 255, 0, 0, 101, 255,
// 0, 108, 0, 255, 0, 108, 0, 255, 111, 0, 0, 255,
// 0, 255, 0, 255, 0, 5, 0, 255, 119, 0, 0, 255,
// 111, 0, 0, 255, 0, 114, 0, 255, 108, 0, 0, 255,
// 0, 0, 100, 255
// ]
If we represent it as a stream of bytes in hexadecimal form:
const {Buffer} = require("buffer");
const serializedString = Buffer.from(serialized).toString("hex");
console.log(serializedString);
// ff0000ff000100ff00ff00ff000500ff000068ff000065ff006c00ff006c00ff6f0000ff00ff00ff000500ff770000ff6f0000ff007200ff6c0000ff000064ff
And, for fun, we can try to read it as text:
console.log(Buffer.from(serialized).toString("utf8"));
// ��☺���♣�h�e�l�l�o���♣�w�o�r�l�d�
Yes, there are a lot missing characters, because remember that this is a binary format. It's not meant to be read as text! But you can still recognize the characters of "hello" and "world" there. There are some emojis too, but those are entirely accidents—some of our byte sequences formed valid Unicode codepoints!
Next up, before we print this as an image, let's write a deserializer for this. Supposing we're given only the hex string, and need to decode it. It's a bit tricky, because even though we're given a string, it's not really a string. It's a sequence of bytes. And in Node.js, Buffer is the class you want to use when dealing with a stream of bytes. So we first convert to a buffer. Then we make sure to read four bytes at a time. If the byte is red (FF0000FF), we know an object is coming next. If it's green, it's a string. If it's neither of those, then we search for the truth byte, the first non-zero byte and extract that as the value.
function deserialize(buffer, start = 0) {
let original;
let [type, nextIndex] = getNextFourBytes(buffer, start);
if (Array.from(type).toString() === RED.toString()) {
original = {};
let keyCount;
[keyCount, nextIndex] = getTruthByte(buffer, nextIndex);
while (keyCount--) {
let key, value;
[key, nextIndex] = deserialize(buffer, nextIndex);
[value, nextIndex] = deserialize(buffer, nextIndex);
original[key] = value;
}
} else if (Array.from(type).toString() === GREEN.toString()) {
let length;
[length, nextIndex] = getTruthByte(buffer, nextIndex);
const characters = [];
for (let i = 0; i < length; i++) {
[character, nextIndex] = getTruthByte(buffer, nextIndex);
characters.push(character);
}
original = characters.map(v => String.fromCharCode(v)).join("");
}
return [original, nextIndex];
}
function getNextFourBytes(buffer, start) {
return [buffer.slice(start, start + 4), start + 4];
}
function getTruthByte(buffer, start) {
const [slice, nextIndex] = getNextFourBytes(buffer, start);
return [Array.from(slice).find(v => v != 0) || 0, nextIndex];
}
const buffer = Buffer.from(serializedString, "hex");
const [deserialized] = deserialize(buffer);
console.log(deserialized);
// { hello: 'world' }
You'll notice that we pass and receive a nextIndex parameter. This is important because we're passing a stream of bytes, so we need to keep track of where we stopped and where we're to continue from.
Finally, let's prove that our serialization really produced an image. We'll work with our serialized array of bytes. We create an ImageData object and fill its pixels with the byte values. However, our image will be only one pixel high, so we set its height to something visible, like 100px, and repeat the byte values in each row (ie our serialization produced a 64-byte array, so pixels 0, 64, 128, and so on will have the same colour)
const numberOfBytes = serialized.length;
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext('2d');
const height = 200;
const imageData = ctx.createImageData(numberOfBytes/4, height);
for (let i = 0; i < numberOfBytes; i++) {
for (let h = 0; h < height; h++) {
imageData.data[i + numberOfBytes * h] = serialized[i];
}
}
ctx.putImageData(imageData, 0, 0);
Viewing this in a browser gives:
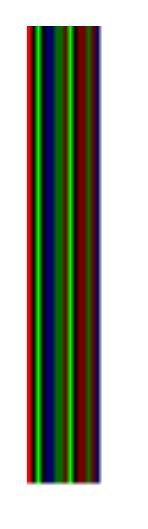
Not a pretty image, sure, but definitely an image. You can see the bright red at the start, denoting an object, then the two green stripes later on, denoting strings.
And if we try to serialize something with nested objects (like {hello: {nested: {nested: "world"}}}), we get this:

You can see the pattern repeated: the three bright red stripes for the three objects, and the four bright green stripes (indicating the starts of "hello", "nested", "nested", and "world"), plus all the other pixels for the characters.
You can see the full code in this gist, and here's a playground to try it out.
Finis
So that's it. We've had some fun creating our own format. It was terribly inefficient (64 bytes for {hello: "world"}, which is only 17 bytes in JSON), but it was pretty fun to explore what that could be like. If you'd like to read more boring details about serialization formats, Wikipedia has a good comparison of popular formats.
Addendum: the V8 JavaScript engine (used by Node.js and Chrome) has its own serialization format. It is used internally, when objects need to be passed across worker threads or stored somewhere (MDN). Here are the docs for the Node.js API.
I write about my software engineering thoughts and experiments. Want to follow me? I don't have a newsletter; instead, I built Tentacle: tntcl.app/blog.shalvah.me.
